Appearance
网页被解析的过程
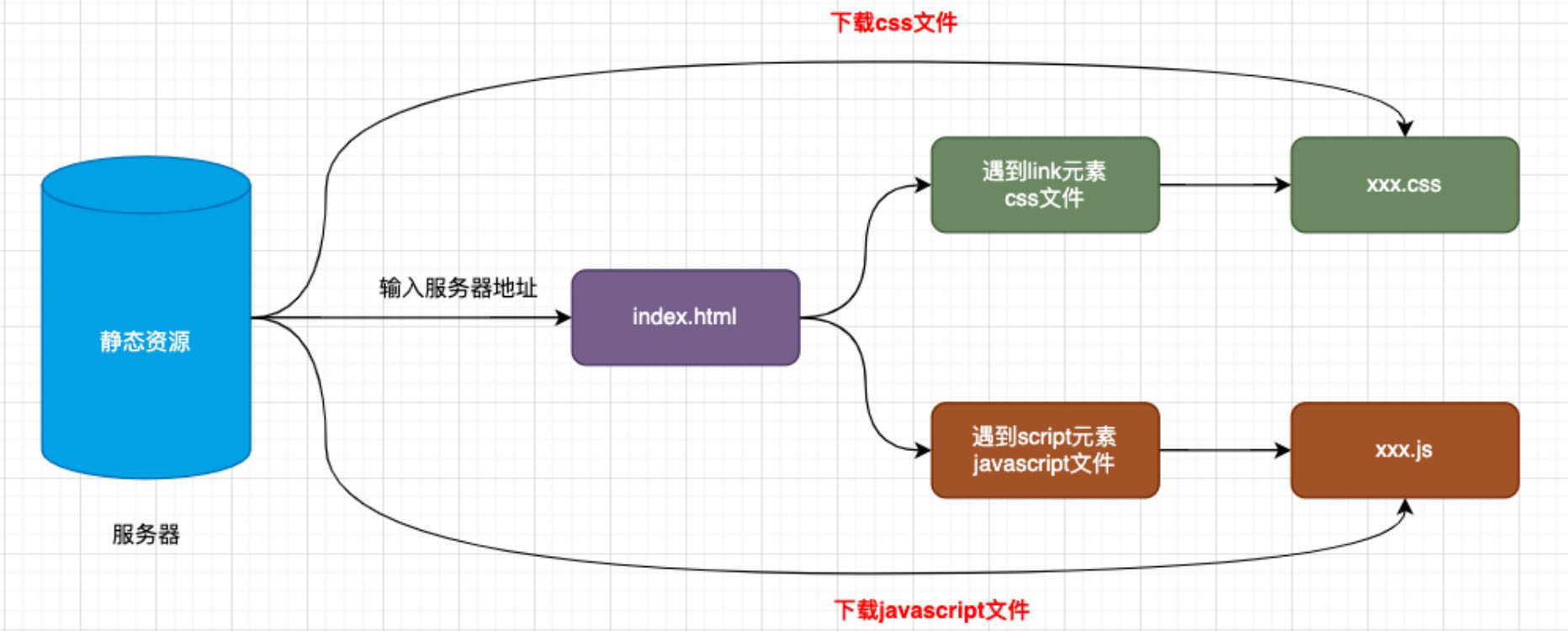
服务器下载资源的过程,先下载 index.html,遇到 JavaScript、CSS 再下载它们:
浏览器的内核
- 常见的浏览器内核有
- Trident(三叉戟): IE、早期的 360 安全浏览器、早期的搜狗高速浏览器、早期的百度浏览器、早期的 UC 浏览器;(微软已经放弃);
- Gecko( 壁虎): Mozilla Firefox;
- Presto(急板乐曲)-> Blink (眨眼): Opera;
- Webkit: Safari、移动端浏览器(Android、iOS);
- Webkit -> Blink: Google Chrome,Edge,360 极速浏览器,搜狗高速浏览器等国内浏览器;

- 我们经常说的浏览器内核指的是浏览器的排版引擎:
- 排版引擎(layout engine),也称为浏览器引擎(browser engine)、页面渲染引擎(rendering engine)或样版引擎。
也就是一个网页下载下来后,就是由渲染引擎来帮助我们解析的。
渲染引擎如何解析页面呢?
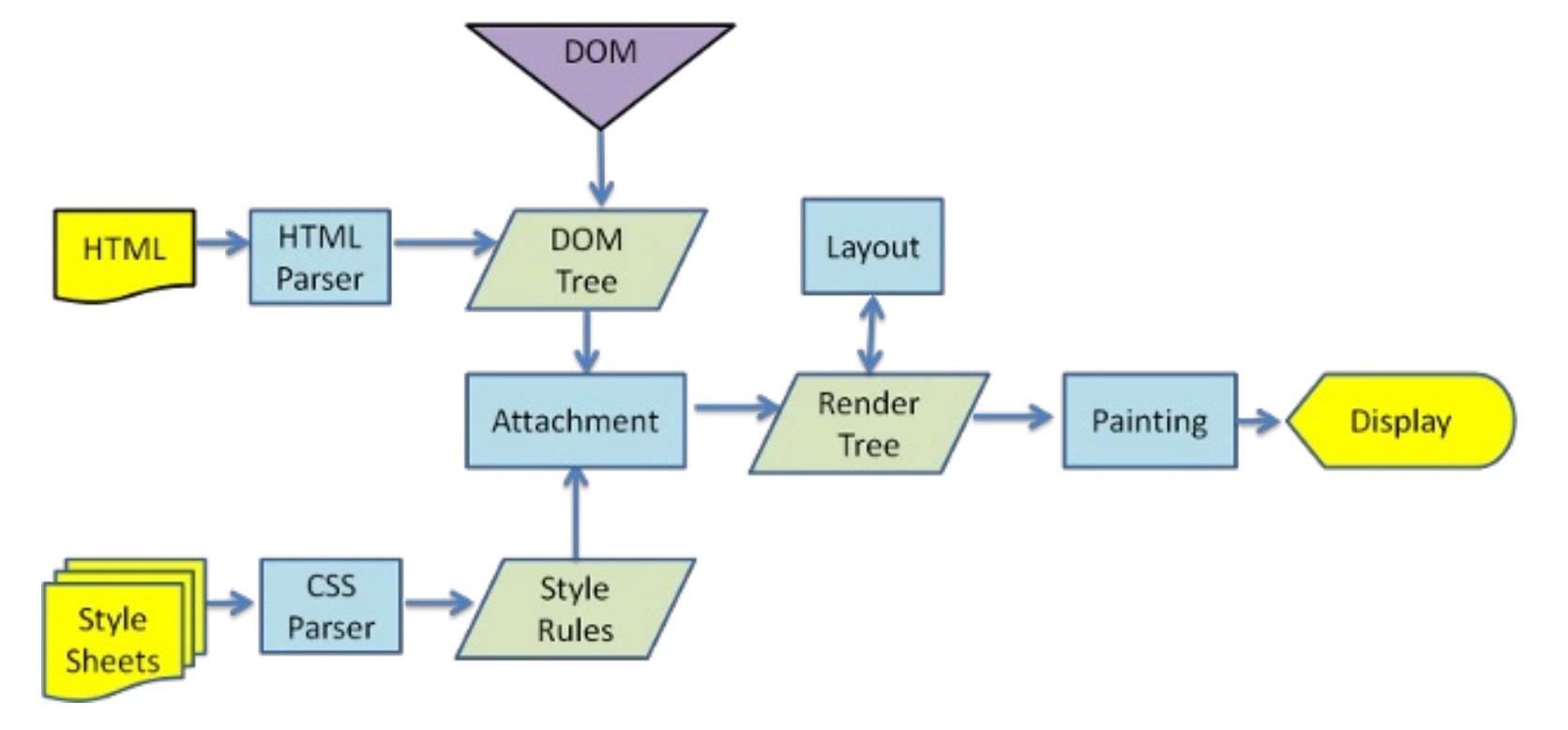
解析一: HTML 解析过程
因为默认情况下服务器会给浏览器返回index.html文件,所以解析HTML是所有步骤的开始:
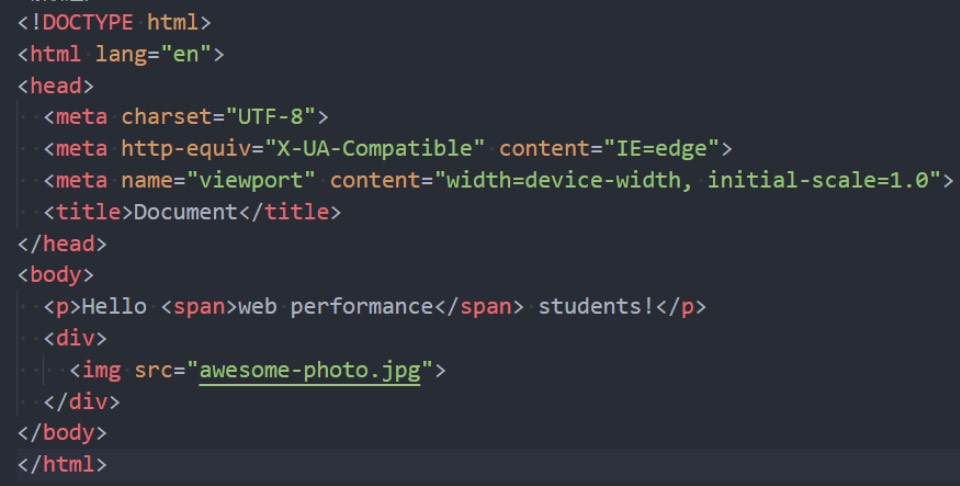
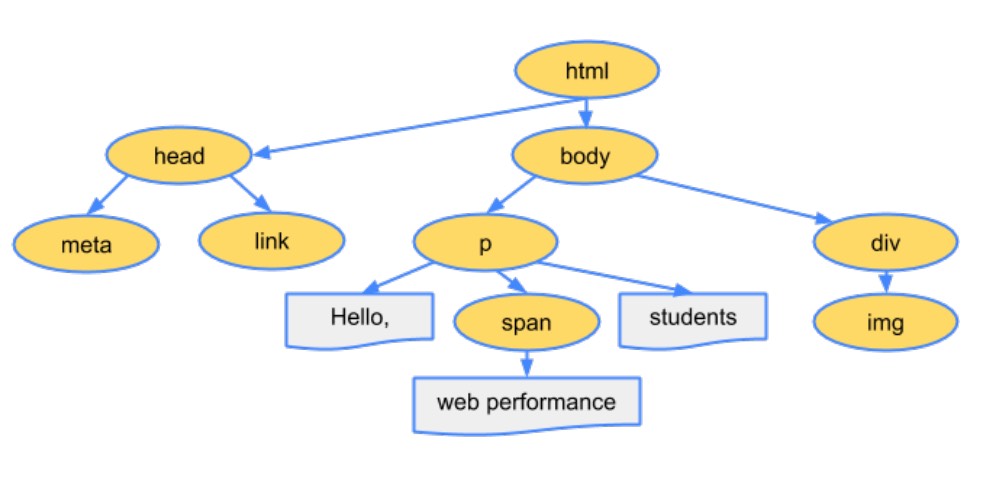
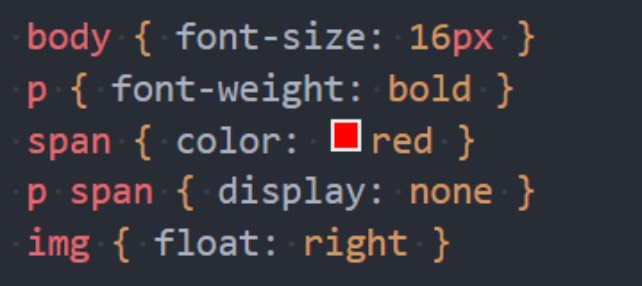
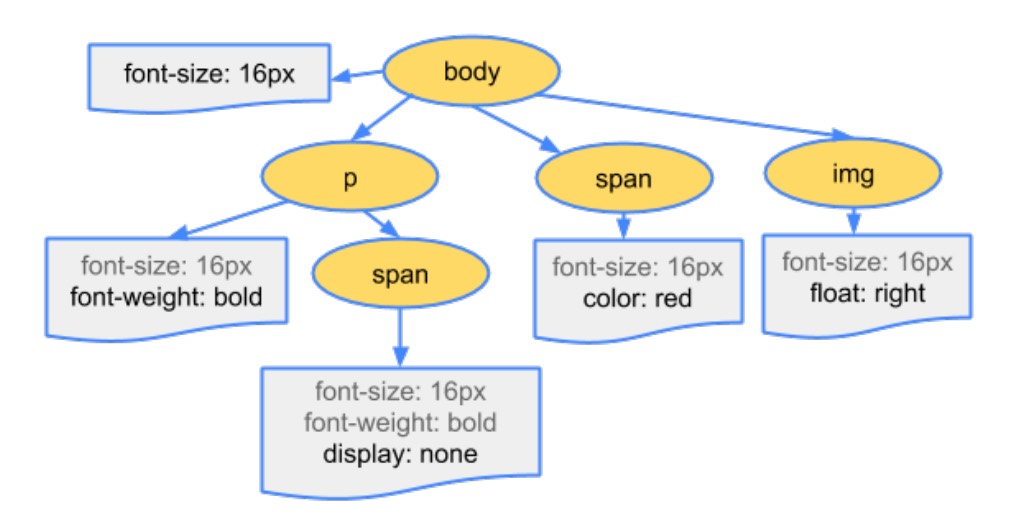
解析二: 生成 CSS 规则
解析三: 构建 Render Tree
当有了DOM Tree和CSSOM Tree后,就可以两个结合来构建Render Tree了
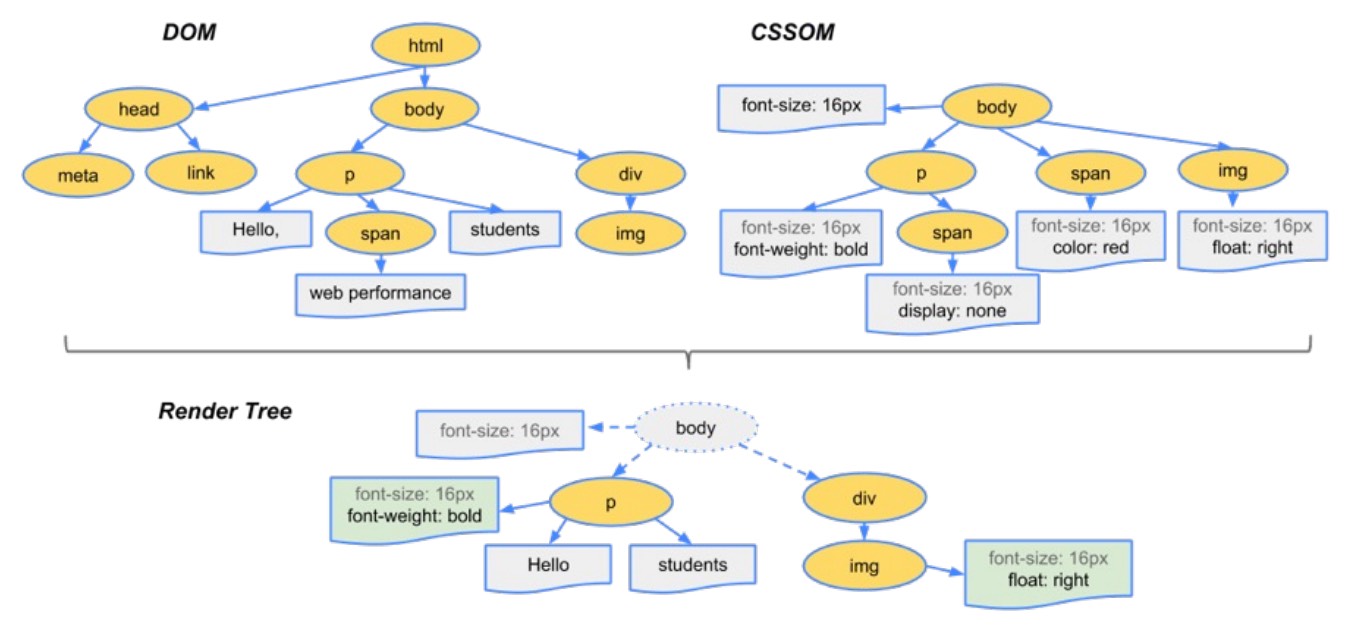
注意一:link 元素不会阻塞 DOM Tree 的构建过程,但是会阻塞 Render Tree 的构建过程,这是因为Render Tree在构建时,需要对应的CSSOM Tree;
注意二:Render Tree 和 DOM Tree 并不是一一对应的关系,比如对于display为none的元素,压根不会出现在render tree中;
解析四 – 布局(layout)和绘制(Paint)
第四步是在渲染树(Render Tree)上运行**布局(Layout)**以计算每个节点的几何体。
- 渲染树会表示显示哪些节点以及其他样式,但是不表示每个节点的尺寸、位置等信息;
- 布局是确定呈现树中所有节点的宽度、高度和位置信息;
第五步是将每个节点绘制(Paint)到屏幕上
- 在绘制阶段,浏览器将布局阶段计算的每个 frame 转为屏幕上实际的像素点;
- 包括将元素的可见部分进行绘制,比如文本、颜色、边框、阴影、替换元素(比如 img)

Match selectors: 浏览器遍历 CSSOM,将选择器与 DOM 树中的元素匹配。这个过程决定了哪些 CSS 规则应用于哪些 DOM 元素。
Compute style: 在选择器匹配后,浏览器计算每个元素的最终样式。这包括计算具体的样式值,处理继承的样式以及解析因层叠产生的任何冲突。
Construct frames: 这通常是指生成布局树,它是渲染树的一部分,仅包含要布局和绘制的元素。这一步骤涉及确定文档的结构层次和包含块。
TIP
包含块: 指一个元素在哪个区域里面排列。
一个元素会生成四个盒子:margin、border、padding、content,如果这个元素有一个子元素,那这个子元素的包含块就是父元素的内容盒(content),而不能说是父元素。
如果一个元素是固定定位,那就要看它的祖先元素中有没有变形元素(transform),如果有,那它的包含块就是这个变形元素,如果没有,那包含块就是视口。
布局树和渲染树是有微小的差异,布局树是渲染树的子集,不包含渲染树中元素的颜色、背景、阴影等信息